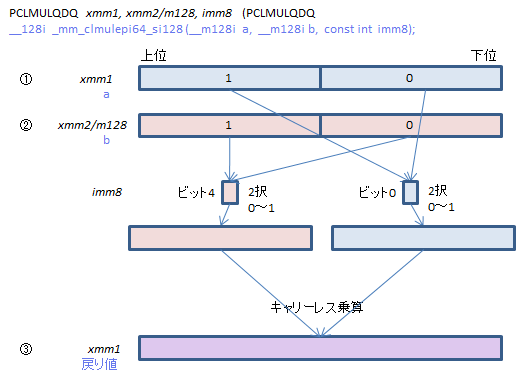
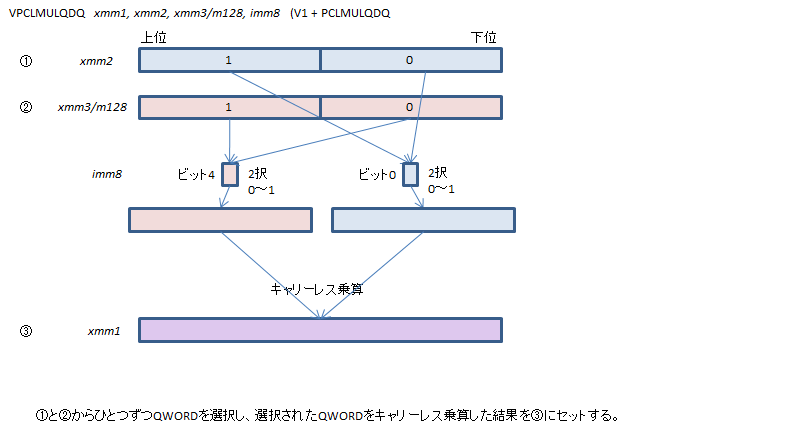
PCLMULQDQ - Packed CarryLess MULtiplication Qword DoubleQword
キャリーレス乗算は一部の暗号アルゴリズムで使われる特殊な演算です。
x86/x64 SIMD命令一覧表
フィードバック
ホームページ
http://www.officedaytime.com/