第2章 フィボナッチ数列
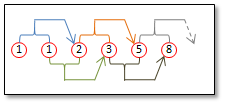
左はフィボナッチ数列の最初の20項目を出力するプログラムです。フィボナッチ数列とは、右のように、直前の2項の和がその項目の値になっている数列です。
10行目の「CALL OUTDEC」は符号なしの数値を10進数で出力するサブルーチンを呼び出しています(これはCASL II に標準的についてくるライブラリというようなものではまったくなくて、こちらで用意したものです。上の「例題を実行してみる」をクリックすると、この部分も含めたソースが表示されます)。サブルーチン内の処理についてはとりあえず今は気にしないでください(4章と5章で説明します)。
汎用レジスタ

COMET II コンピュータには8つの汎用レジスタがあります。 汎用レジスタは各1語の大きさで、GR0〜GR7の名前がついています。
汎用レジスタはCPUの中にある小さなメモリのようなもので、プログラミング上は定義済みの変数のように使えます。 一般的にレジスタはメモリより短い命令で速くアクセスできます。 アセンブラで効率のよいプログラムを書くにはレジスタをいかにうまく使うかがポイントになります。 プログラムを起動したときの汎用レジスタの初期値は不定です。
8行目のLDは、メモリ内の語から汎用レジスタに値をロードする命令です。LDはLoaDの意味です。 第2オペランドで指定されたアドレスにある語の内容を第1オペランドの汎用レジスタにコピーします。 この場合はCOUNTのラベルのついた語の内容、すなわち20がGR2にロードされます。 COUNTの内容は変わりません。
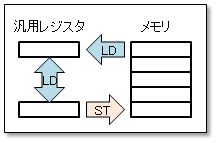
LD命令では、第1オペランドは汎用レジスタでなくてはなりません。第2オペランドは汎用レジスタでもメモリアドレスでもかまいません。第2オペランドにレジスタを指定すれば、レジスタ間の値のコピーにも使えます。
逆に、汎用レジスタの値をメモリに格納するにはST命令を使います。STはSToreの意味です。第1オペランドのレジスタの値を第2オペランドのアドレスに格納します。 CASL II の機械命令では、唯一、ST命令だけが、第2オペランド側に値を格納します。
| コピー先←コピー元 | 命令 | 備考 |
|---|---|---|
| レジスタ←メモリ | LD レジスタ,メモリ | |
| レジスタ←レジスタ | LD レジスタ1,レジスタ2 | レジスタ2からレジスタ1へコピー |
| メモリ←レジスタ | ST レジスタ,メモリ | この命令だけ、第2オペランドがコピー先になる |
| メモリ←メモリ | × | いったんレジスタへLDしてからSTする必要がある |
加減算

14行目のADDLは符号なし加算を行う命令です。第1オペランドと第2オペランドを加えて結果を第1オペランドに格納します。 ADDLの「L」は「Logical」の略ですが、ここでいうlogicalには符号なし演算という以上の意味はありません。 C/C++でいうunsignedのことです。論理和(OR)という意味ではありません。
符号付き加算を行う場合はADDA命令を使います。 ADDAの「A」は「Arithmetic」の略ですが、ここでいうarithmeticには符号付きという以上の意味はありません。 C/C++でいうsignedのことです。
15行目のSUBLは符号なし減算命令です。第1オペランドから第2オペランドを引き結果を第1オペランドに格納します。減算についても符号付き演算を行うSUBA命令があります。
加減算命令では第1オペランドは汎用レジスタである必要があります。第2オペランドは14行目のように汎用レジスタを指定することも15行目のようにメモリアドレスを指定することもできます。メモリアドレスを指定した場合は、そのアドレスにある語の内容が演算対象になります。 15行目ではGR2からC1番地の内容、すなわち1が引かれます。
リテラル
15行目で1を引くために、3行目でDC命令を書きそこに1を入れています。 定数を使うたびにいちいちDC命令を書いてラベルをつけるのは面倒なので、CASL II にはリテラルという機能が用意されています。
SUBL GR2,=1
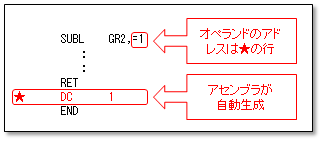
のように定数の前に=をつけて書くと、アセンブラはその定数を定義するDC命令を自動生成して、そのアドレスを命令のオペランドとして使います。この機能により、定数を定義するDC命令をソース中に書く必要がなくなります。またラベル名を考える必要もなくなります。リテラル定数の実体はプログラムの最後(END命令の場所)に確保されます。
リテラルは単にコーディングの手間を省いてくれるだけです。 定数が別に確保されるという点ではDC命令を手で書くのと何も変わりませんので、ソース行数は減りますがオブジェクトプログラムの語数が減ったりするわけではありません。
オペランド指定に注意
上の=をつけずに
SUBL GR2,1
のように書くと、メモリの0001番地の内容をGR2から引くという意味になります。
一般的にはプログラミング時点では特定の番地に何が入っているかはわかりませんので、アドレスは数字で直接指定せずに、ラベルで指定します。ラベルを使うことにより、プログラムがどこにロードされても、そのラベルのついた語が配置されたメモリアドレスを正しく指定できます。
しかし、上のように数字を直接書いても文法上はOKで、こう書いてもアセンブラはエラーにすることはありません(定数をメモリアドレスとして解釈して、正常にアセンブルを終了します)。ただ、実行時に1を引く代わりに何が入っているかわからない0001番地の内容を引いてしまい、誤動作するだけです。 =の付け忘れには気をつけてください。
フラグと条件分岐

LD命令や加減算命令を実行すると、結果が第一オペランドに格納されるほかに、結果の値に応じて、CPUの中の「フラグレジスタ(FR)」という部分に値が設定されます。 フラグレジスタには以下の3つのビットがあり、命令を実行するたびにそれぞれ次のように設定されます。
| フラグ名 | 意味 | 働き |
|---|---|---|
| ZF | ゼロフラグ | 値がゼロのとき1に、ゼロ以外のときに0に設定されます(ゼロのときゼロでなく、ゼロでないときゼロ、という点に要注意)。 |
| SF | サインフラグ | 値の最上位ビット(符号)が1であるときに1に、0であるときに0に設定されます。 符号なしの加減算でも最上位ビットによってSFの値が決まります。 |
| OF | オーバーフローフラグ | 加減算命令で演算結果がオーバーフローしたときに1に、しないときに0に設定されます。 符号つき演算では演算結果が-32768〜32767の範囲を超えたとき、符号なし演算では演算結果が0〜65535の範囲を超えたときにオーバーフローになります。 LD命令を実行すると、OFは0になります |
設定されたフラグは、フラグを変える命令を次に実行するまで、フラグレジスタの中に保存されます。
条件分岐命令を使うと、フラグが特定の値である場合に分岐することができます。
16行目のJNZ命令は、ZFが0のとき、すなわち直前の演算結果が0でないときに、オペランドで指定したアドレスに分岐する命令です。 NZは「notゼロ」の意味です。
この例では、15行目でGR2から1を引いた結果が0でないとき、LOOPというラベルのついた番地、すなわち10行目に分岐します。 結果が0である場合は分岐は行われずに、そのまま下の命令に進みます。 これにより10行目から16行目を20回ループする処理を実現しています。
JNZ命令を含めて、CASL II の分岐命令には以下のものがあります。
| 命令 | 分岐条件 | 働き | 何の略か |
|---|---|---|---|
| JNZ | ZF=0 | 演算結果が0でないとき分岐します。 | Not Zero |
| JPL | ZF=0かつSF=0 | 演算結果が正のとき分岐します。 | PLus |
| JMI | SF=1 | 演算結果が負のとき分岐します。 | MInus |
| JZE | ZF=1 | 演算結果が0のとき分岐します。 | ZEro |
| JOV | OF=1 | 演算でオーバーフローが起きたとき分岐します。 | OVerflow |
| JUMP | 無条件 | 必ず分岐します。 |
分岐条件のフラグについては、理解はしておく必要がありますが、普段プログラムを読み書きするときは、「何の略か」と「働き」だけを考えればよいでしょう。頭がこんがらがりますので。
条件分岐命令ではフラグは変わりませんので、前のフラグの値が残ります。 演算命令の後に条件分岐命令を続けて書けば一回の演算の結果について複数の条件を判定できます。
ADDA GR1,GR2 ; 加算・・・ZF,SF,OFがここで設定される
JOV OVERFLOW ; オーバーフローしたらOVERFLOWへジャンプ
JPL PLUS ; 結果が正ならPLUSへジャンプ
JMI MINUS ; 結果が負ならMINUSへジャンプ
; 分岐しなかったとき(ゼロのとき)ここにくる
構造化
CASL II では、条件によってラベルに分岐することでプログラムの流れを制御することになります。 高級言語のようにgotoレスな形で構造化することはできません。
だからといって上へ下へと自由自在に分岐してはプログラムの流れが見づらくなります。 下から上への分岐はループする箇所などやむをえない場合以外は行わないようにすると多少は見やすくなるかと思います。
アセンブラのループはカウントダウン
高級言語でループを書く場合、
- 最初にカウンタに0を入れておく
- 1回ループするたびにカウンタをインクリメント
- 脱出条件はカウンタと終値を比較する
のようにするのが普通ですが、アセンブラでは、ただ回数をカウントするだけなら
- 最初にカウンタに回数を入れておく
- 1回ループするたびにカウンタをデクリメント
- 脱出条件はカウンタが0かどうかで判断
という方法がよく使われます。
こうすると、脱出条件の判断にはデクリメントの際に設定されたフラグをそのまま利用できるため、比較命令をひとつ省くことができるからです。 最初は違和感があるかもしれませんが、これは定石なので覚えておきたい手法です。
ゼロクリア
| 命令 | 意味 | オペランドの 各ビットの値 |
||
|---|---|---|---|---|
| 第1 | 第2 | 結果 | ||
| AND | 論理積 | 0 | 0 | 0 |
| 0 | 1 | 0 | ||
| 1 | 0 | 0 | ||
| 1 | 1 | 1 | ||
| OR | 論理和 | 0 | 0 | 0 |
| 0 | 1 | 1 | ||
| 1 | 0 | 1 | ||
| 1 | 1 | 1 | ||
| XOR | 排他的論理和 | 0 | 0 | 0 |
| 0 | 1 | 1 | ||
| 1 | 0 | 1 | ||
| 1 | 1 | 0 | ||
7行目のXORは、排他的論理和を求める命令です。 XOR命令は、第1オペランドと第2オペランドのビット単位の排他的論理和を計算して第1オペランドに格納します。 この例ではGR1とGR1の排他的論理和をGR1に格納します。 これでGR1には0が格納されます。 0と0の排他的論理和は0、1と1の排他的論理も0なので、ふたつの同じ値の排他的論理和を取ると各ビットが0になります。 GR1のもとの値がいくつであっても、「XOR GR1,GR1」を行うと、必ずGR1はゼロになります。
レジスタに値0を入れるためには、定数0を定義して、その語をロードしてもかまいませんが、それだと命令語のほかに定数0を定義するための1語が別に必要になります。 そのアドレスを指定するために命令も長くなり、メモリアクセスのために余計な実行時間がかかります。
高級言語ではプログラムの可読性のために多少の無駄は許されるという考え方がありますが、アセンブラプログラミングではこのような無駄は極力排除するのが普通です。 可読性のほうが大事なら高級言語を使ったほうがましということです。 そこで、ゼロをロードする代わりにXOR命令を使ってゼロクリアを行います。 これは決してトリッキーなテクニックなどではなく、アセンブラプログラミングではごく普通に行われる方法です。
XORの代わりに引き算命令を使う手もあります。 「SUBA GR2,GR2」とするとGR2はゼロになります。 こちらもよく使われます。 SUBLでもOKです。
CASL II の論理演算命令にはXORのほかにANDとORがあります。 ビット単位の論理積と論理和をとって第1オペランドに格納します。 XOR、AND、OR命令では、加減算と同様に第1オペランドは汎用レジスタである必要があります。第2オペランドは汎用レジスタでもメモリアドレスでもかまいません。 演算結果に応じてZF(すべてのビットがゼロのときのみ1)とSF(最上位ビットの値が1のとき1)が設定されます。OFは必ず0になります。
実行開始アドレスの指定
START命令のオペランドでプログラム中のラベルを書くと、そのラベルが実行開始番地になります。 2行目 のSTART命令ではオペランドをENTRYとしていますのでENTRY番地がこのプログラムの実行開始番地になります。 ENTRYより上の部分にデータを書いてもその部分は実行されません。 高級言語ではデータ、実行文の順で書くのが普通なのでこのように書いたほうが読みやすいかもしれません。 以降本ドキュメントではこの書き方を使います。
STARTで指定するのは、STARTで始まるプログラムが呼び出されたとき、どこから実行を開始するか、ということです。サブルーチンを含めて複数のプログラムがある場合の全体の実行開始アドレス(メインプログラムとなるプログラムの入り口)の指定方法は処理系により異なりますので、お使いの処理系のマニュアルをご覧ください。DCasl2の場合は上の「例題を実行してみる」をご覧ください。