第3章 レールフェンス暗号
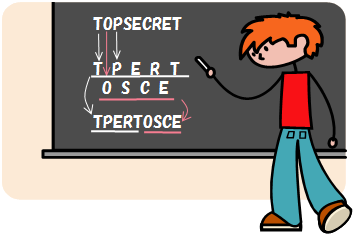
左のプログラムは、入力された文字列を「レールフェンス暗号」で暗号化して、できた文字列を出力するプログラムです。レールフェンス暗号とは、右のような、ごく原始的な暗号です。
左のプログラムでは、入力文字の1文字目から1文字とばしながら上段にあたる文字を取り出して暗号文の前半を作ったあと、入力文字の2文字目から1文字とばしながら下段にあたる文字を取り出して暗号文の後半を作っています。
アセンブラは読みにくい
左のプログラムを見て、もう一見してなんだかわからない、という感じがするかもしれません。でもそれが普通です。アセンブラプログラムは読みにくいものなのです。
「難しくない」と目次ページで言ったじゃないかって? そう、難しくはないのですが、読みにくいのです。プログラミング言語の進化は読みやすさを追求してきた結果です。アセンブラは進化のはじめの段階の言語ですから読みにくいのは仕方がありません。アセンブラプログラムを理解するにはじっくりと一行一行精読していく必要があります。他の言語のプログラムのようにすらすら読めないとしても、それは決してアセンブラ言語に適正がないとかそういうことではありません。
試験ではアセンブラの読みにくさを十分すぎるほど考慮して、他の言語よりずっと短いプログラムが出題されると思います。ここで投げ出さずに、ぜひじっくりと説明とプログラムを読んでみてください。この章を理解すれば、アセンブラ言語の核心をつかんだも同然です。
連続領域を確保
3行目、4行目、5行目にあるDS命令は、オペランドで指定した語数の連続したメモリを確保する命令です。実行文ではなくスタティックなメモリを確保するアセンブラ命令です。
オペランドには10進数をひとつだけ指定できます。 3行目、4行目では256語が、5行目では1語が確保されます。 語の初期値は不定です。 DS命令につけたラベルは、確保した語の先頭のアドレスをあらわします。
指標レジスタと実効アドレス
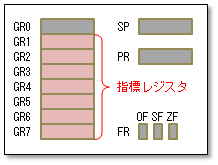
前章までの例題では、メモリのオペランドはすべてラベルだけで指定していました。これだと、命令の働く先の語はプログラミング時点で決まってしまい、実行中に変えることができません。DS命令で確保したメモリの中の各語を配列要素のようにひとつずつ処理したいようなときはどうしたらいいでしょうか?
その問題を解決するのが「指標レジスタ」です。レジスタに入っているアドレスや数値を使ってオペランドのアドレスを指定することができます。配列の添字や、 C/C++でいうポインタのような働きをさせることができます。指標レジスタという名前の特別なレジスタがあるわけではなく、汎用レジスタGR1〜GR7を指標レジスタとして使います。 指標レジスタというのは、レジスタの名前ではなく、使い方を表す言葉です。 GR0は指標レジスタとしては使えませんので注意してください。
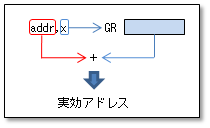
CASL II ではメモリアドレスのオペランドは「addr,x」の形で指定することができます。 addrはアドレスの意味ですが、ラベルでも数値でもかまいません。 xは指標レジスタ(GR1〜GR7)です。指標レジスタの内容とaddrを加えたものを「実効アドレス」と呼びます。実効アドレスが実際にその命令の働く先のアドレスです。
CPUが 実効アドレスを計算するときはaddrとxの値をただ足し算するだけです。しかし、addrとxの両方にアドレスを指定したりしても、足された結果は有効なアドレスにはなりません。指標レジスタの有効な使い方としては、基本的に以下のようになるでしょう。
| 指標レジスタの使い方 | addr | 指標レジスタの内容 | 説明 | 図解 |
|---|---|---|---|---|
| ポインタとしての使い方 | 0 | アドレス | 実効アドレス=0+指標レジスタの値、つまり、指標レジスタの値がそのまま実効アドレスになります。 |  |
| 数値 | アドレス | レジスタの指しているアドレスからの相対アドレスを定数で指定できます。 負の数を指定すれば指標レジスタより前の語を指定することもできます。 |
 |
|
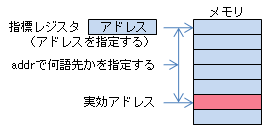
| 配列添字のような使い方 | ラベル | 0からのインデックス | ラベルのついたアドレスから何語目かを指標レジスタで指定できます。 | 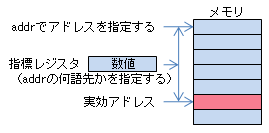 |
CASL II では型のようなものはありませんので、1を足せばアドレスが1増え、これは1語先のアドレスになります。C/C++のようにポインタに1を足したときポインタの値がいくつ増えるかがポインタの型によって変わる、というようなことはありません。
16行目の「ST GR4,0,GR3」はポインタとしての使い方です。「addr,x」の部分が「0,GR3」になってるので、指標レジスタGR3の内容がそのまま実効アドレスになります。「ST GR4,0,GR3」は、GR3の指している番地にGR4の内容を格納するという命令になります。GR3には11行目のLAD命令であらかじめOBUFのアドレスをロードしてあります(LAD命令については後述します)。
15行目の「LD GR4,IBUF,GR2」は配列添字のような使い方です、IBUFというラベルのついたアドレスにGR2の値を加えたものが実効アドレスになります。 このLD命令により、3行目の「IBUF DS 256」で確保した256語のうち、(GR2)番目の語(0から数えて)がGR4にロードされます。
8行目の「LD GR0,LEN」にはaddr,xの「,x」の部分がありませんが、これは指標レジスタを指定しない形式です。指標レジスタがない場合はaddrの部分がそのまま実効アドレスになります。この章より前の例題プログラムで使っているメモリアドレスの指定はすべてこの形式でした。
先頭アドレスと添字を両方可変にしたい場合はどうしたらいいでしょうか? CASL II では指標レジスタはひとつしか指定できませんので、その場合は別途ADDL命令などでレジスタを足し算して実効アドレスを計算してから、その計算結果をポインタのように使うしかありません。
LAD(Load ADdress)命令はアドレスをロードする命令?
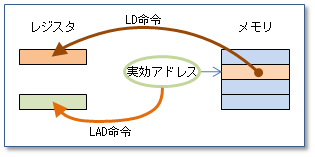
11行目のLAD命令はオペランドの実効アドレスをレジスタにロードする機械命令です。 LD命令はメモリ内の実効アドレスにある語の値をロードする命令ですが、それに対してLAD命令は実効アドレス自体をロードします。
11行目の「LAD GR3,OBUF」ではOBUFのアドレスをGR3にロードしています。 これによりGR3は4行目で確保している256語の最初の語へのポインタになります。 16行目ではGR3を指標レジスタとして使い、GR3の指しているアドレスにGR4の内容(入力バッファから取ってきた文字)をストアしています。 addr,xのaddrの部分が0ですから、GR3の内容がそのまま実効アドレスになります。
17行目の「LAD GR3,1,GR3」はGR3に1を加える処理です。 この命令の実効アドレスはGR3の内容に1を加えた値、すなわち、GR3の指している語の次の語です。 この実効アドレスそのものがGR3にロードされますから、結果としてGR3に1が加えられます。このプログラムでは、この方法で出力バッファのポインタを1ずつ進めて、出力バッファに値を格納していきます。
Load ADressという名前に反して、LAD命令でロードできるのはアドレスに限りません。アドレスでもなんでもない、ただの定数でもロードできます。前章のプログラムで、定数1をロードするために、このようにしていました。
C1 DC 1 ; 定数1
ENTRY LD GR0,C1
これは以下のように置き換えられます。
ENTRY LAD GR0,1
この命令では1番地のアドレス(すなわち1)がGR2にロードされます。 前章で書いたように一般的には特定のアドレスに何があるかはプログラミング段階ではわかりませんから、このように数値でアドレスを直接指定することはしません。 ただし、LAD命令は、アドレスをロードするだけで1番地の語にはなんの作用もありませんから、LAD命令をこのように使うのはまったく問題ありません。 これにより定数1を入れた別の語を確保せずにすみ無駄が省けます。
18行目の「LAD GR2,2,GR2」は、GR2に入っている値に2を加えたものがGR2に格納されます。すなわちGR2に2が加わります。ここでGR2に入っているのは、配列の添字のようなものであり、アドレスではありませんが、実効アドレスの計算は要するにaddrとxを足し算をしているだけなので、LAD命令をこのように使えば、アドレス以外の数値でも加算ができます。2の代わりに負の値を書けば減算も可能です。
22行目の「LAD GR1,1,GR1」は、レールフェンスの段のカウンタ(上段=0、下段=1)をインクリメントしています。これはLAD命令をただのカウンタのインクリメントに使っています。
LAD命令はこのように定数のロードや加減算にも使えます。 LD/ADDL/SUBL命令と違って定数用に別の1語を確保する必要がないので効率よくロードや加減算を行うことができます。第1オペランドと指標レジスタに別のレジスタを使えば、レジスタに定数を加えた値を別のレジスタに入れる、というような動作も1命令でできます。
一般的に、ソフトウェアの設計では、用意された機能を本来の目的以外のことにみだりに使うのは好ましくないかもしれません。 しかし、アセンブラプログラミングでは機械命令をこのように流用することは普通のことです。 プログラマは各命令の動作に精通している必要があります。
LAD命令はフラグを変えません。 そのため、演算結果によって条件分岐をしたい場合は使えません。もうひとつ、GR0は指標レジスタとして使えないため、「LAD GR0,1,GR0」のようにしてGR0に定数を加えることはできませんので注意してください。
IN命令
7行目のIN命令は入力装置から1行の文字列を読み込むマクロ命令です。 第1オペランドでは文字列を受け取るバッファのアドレスを指定します。 バッファは256語の長さが必要です。 第2オペランドでは入力された行の長さを受け取る語のアドレスを指定します。
7行目を実行すると、キーボードなどから(シミュレータの設定によります)1行入力を行い、入力された文字列がIBUF番地から始まる最大256語に、文字列の長さがLEN番地の語に格納されます。 IBUFには1文字が1語に、各語の下位8ビットには文字コードが、上位8ビットには0が格納されます。 改行コードなどは入りません。 CASL II では256文字以上の行を入力することはできません。
EOF(ファイルの終わり)に達すると、LENには-1が格納されます。
比較命令
19行目のCPLは符号なし比較を行う機械命令です。 第1オペランドと第2オペランドを比べて、その結果によりフラグを設定します。 この命令はフラグを設定するだけの命令です。 その直後に条件分岐命令をおくことにより、比較結果により分岐することができます。 第1オペランドは汎用レジスタである必要があります。 第2オペランドは汎用レジスタでもメモリ内の語でもかまいません。 指標レジスタを使うことももちろん可能です。
フラグは以下のように設定されます。 OFは必ず0になります。
| 比較結果 | フラグ | 備考 |
|---|---|---|
| 第1オペランドの方が大きいとき | ZF=0,SF=0 | 演算結果が正のときのフラグの値と同じです。 |
| 第1オペランドの方が小さいとき | ZF=0,SF=1 | 演算結果が負のときのフラグの値と同じです。 |
| 等しいとき | ZF=1,SF=0 | 演算結果がゼロのときのフラグの値と同じです。 |
ちょっとわかりにくいですね。 イメージとしては、Cのstrcmp()関数やC++/C#/Javaによくある比較メソッドなどと同じように、第1オペランドから第2オペランドを引いて結果が正か負か0になる、というふうに考えるとわかりやすいかもしれません(CASL II では実際には減算と比較は異なります。下記参照)。
前章の条件分岐命令の説明と見比べてみれば、以下のことがわかるでしょう。
- 第1オペランドの方が大きいときはJPLで分岐します。
- 第1オペランドの方が小さいときはJMIで分岐します。
- 等しいときはJZEで分岐します。
- 等しくないときはJNZで分岐します。
19、20行目では、入力バッファのインデックスと入力行の長さを比べて、入力行の文字がまだ残っているかを調べています。GR2(インデックス)がLEN(入力行の長さ)より小さければまだ文字が残っていますので、LOOP2のラベルのついた行分岐するという処理になります。
符号なし比較のCPLのほかに、符号付き比較を行うCPA命令もあります。 この場合も大小関係によって同じようにフラグが立ちます。
符号の有無と大小関係

符号なし、符号付きの数値表現と大小についておさらいしておきましょう。
ゼロとの比較
ゼロとの比較は、定数0を書かずに行うことができます。これによりメモリや実行時間の無駄を省けます。
8行目のLD命令は、LEN(IN命令で入力された文字の長さ)をGR0にロードしています。このとき、LENの値に応じて、ZF(ゼロのとき1)とSF(負のとき1)が設定されます。これはゼロとCPAしたときのフラグの立ち方と同じです。CASL II では、LDしただけでゼロとの符号付き比較がついでに行われてしまうのです。
9行目のJMI命令は、IN命令の結果、LENが-1、すなわちEOF(ファイルの終わり)のときに、プログラムを終了させるための処理です。LENが負のときは8行目のLD命令でSF=1が設定されるので、JMIでEXITのラベルのついた行に分岐します。
21行目の「LD GR1,GR1」は、GR1をGR1にコピーしても意味がないように見えますが、これは、GR1の内容によってフラグを立てる、すなわち0と比べるための処理です。レールフェンスの上段を処理したあと、GR1は0になっています。下段を処理した後はGR1は1になっています。0かどうかを調べて、0であればまだ上段だけしか処理がすんでいないので、段ごとのループを繰り返して下段の処理へ進む必要があります。
比較結果は1行飛ばして23行目のJZE命令で判定しています。LAD命令はフラグを変えないので、22行目の命令をはさんでもフラグは残り、その次の条件分岐に使うことができます。効率的なプログラムを書くためにこのようなテクニックを使うことはままあります。たとえば21〜25行目は1行飛ばしを使わずに以下のようにも書けますが、無駄が発生します。
例1:命令数が増えてしまう
LD GR1,GR1 ; 今上段であればZF=1を設定
JNZ OUTPUT
; 今下段なら1行完成
LAD GR1,1,GR1 ;
JUMP LOOP1 ; 下段へ進む
; 暗号文字列完成。出力する
OUTPUT OUT OBUF,LEN ; 出力
例2:定数2用に余計な1語とメモリアクセスが必要
LAD GR1,1,GR1 ;
CPL GR1,=2
; 下段が済んだ?
JMI LOOP1 ; まだなら下段へ進む
; 暗号文字列完成。出力する
OUT OBUF,LEN ; 出力
21行目のようにレジスタに入っている値をゼロと比べるには、LD命令のほかに、「OR GR1,GR1」または「AND GR1,GR1」のようにする方法もあります。これらの命令でもLD命令と同じようにGR1の値を変えずにフラグを設定できます。
比較と減算
CASL II では減算命令と比較命令ではフラグの立ち方が違います。 減算命令ではSF、ZFでは大小関係がわかりませんので減算後にJPL、JMI命令で大小関係を判断することができません。
他のプロセッサでは減算と比較は引かれた結果が格納されるかどうかの違いだけのものがありますが、このようなプロセッサの経験がある方はむしろ間違えやすいかもしれません。 十分ご注意ください。
- 例1:65535と0を符号なし減算・比較した場合
- SUBLの場合は結果は65535(FFFF)で最上位ビットが立っているのでSF=1になります。
CPLの場合は65535の方が0より大きいのでSF=0になります。 - 例2: -32768(8000)と1(0001)を符号付き減算・比較した場合
- SUBAの場合はオーバフローして結果が32767(7FFF)となりSF=0になります。
CPAの場合は-32768のほうが小さいのでSF=1になります。