ADDPD - ADD Packed Double
ADDPD xmm1, xmm2/m128 (S2
__m128d _mm_add_pd(__m128d a, __m128d b)
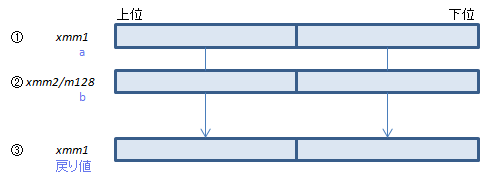
各doubleについて①+②を計算し結果を③にセット
VADDPD xmm1, xmm2, xmm3/m128 (V1
__m128d _mm_add_pd(__m128d a, __m128d b)
VADDPD xmm1{k1}{z}, xmm2, xmm3/m128/m64bcst (V5+VL
__m128d _mm_mask_add_pd(__m128d s, __mmask8 k, __m128d a, __m128d b)
__m128d _mm_maskz_add_pd(__mmask8 k, __m128d a, __m128d b)
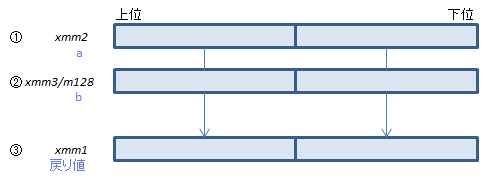
各doubleについて①+②を計算し結果を③にセット
VADDPD ymm1, ymm2, ymm3/m256 (V1
__m256d _mm256_add_pd(__m256d a, __m256d b)
VADDPD ymm1{k1}{z}, ymm2, ymm3/m256/m64bcst (V5+VL
__m256d _mm256_mask_add_pd(__m256d s, __mmask8 k, __m256d a, __m256d b)
__m256d _mm256_maskz_add_pd(__mmask8 k, __m256d a, __m256d b)
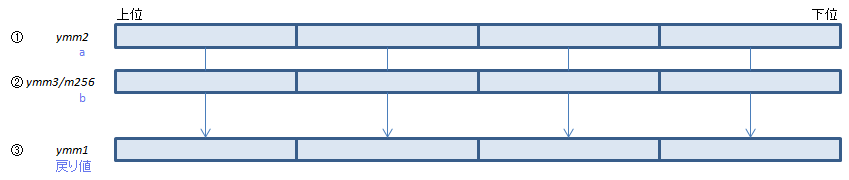
各doubleについて①+②を計算し結果を③にセット
VADDPD zmm1{k1}{z}, zmm2, zmm3/m512/m64bcst{er} (V5
__m512d _mm512_add_pd(__m512d a, __m512d b)
__m512d _mm512_mask_add_pd(__m512d s, __mmask8 k, __m512d a, __m512d b)
__m512d _mm512_maskz_add_pd(__mmask8 k, __m512d a, __m512d b)
__m512d _mm512_add_round_pd(__m512d a, __m512d b, int r)
__m512d _mm512_mask_add_round_pd(__m512d s, __mmask8 k, __m512d a, __m512d b, int r)
__m512d _mm512_maskz_add_round_pd(__mmask8 k, __m512d a, __m512d b, int r)

各doubleについて①+②を計算し結果を③にセット
x86/x64 SIMD命令一覧表
フィードバック