VEXPANDPS - EXPAND Packed Single
VEXPANDPS xmm1{k1}{z}, xmm2/m128 (V5+VL
__m128 _mm_mask_expand_sd(__m128 s, __mmask8 k, __m128 a)
__m128 _mm_maskz_expand_sd(__mmask8 k, __m128 a)
__m128 _mm_mask_expandloadu_sd(__m128 s, __mmask8 k, void* p)
__m128 _mm_maskz_expandloadu_sd(__mmask8 k, void* p)
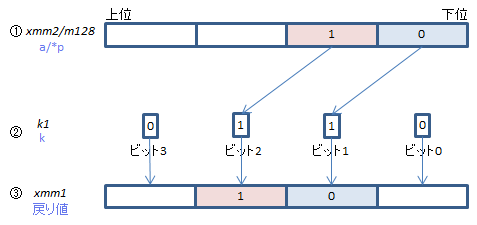
②の対応するビットが立っている③の要素に①の要素を下位からひとつずつ取って格納する
②の対応するビットが立っていない③の要素は、{z}指定がある場合(_maskz_の場合)は0クリア、そうでなければそのまま(sの値が使われる)
VEXPANDPS ymm1{k1}{z}, ymm2/m256 (V5+VL
__m256 _mm256_mask_expand_sd(__m256 s, __mmask8 k, __m256 a)
__m256 _mm256_maskz_expand_sd(__mmask8 k, __m256 a)
__m256 _mm256_mask_expandloadu_sd(__m256 s, __mmask8 k, void* p)
__m256 _mm256_maskz_expandloadu_sd(__mmask8 k, void* p)
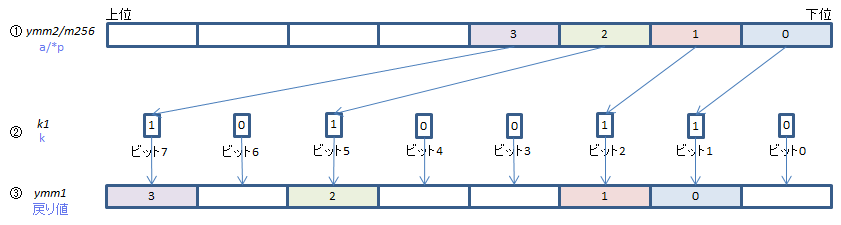
②の対応するビットが立っている③の要素に①の要素を下位からひとつずつ取って格納する
②の対応するビットが立っていない③の要素は、{z}指定がある場合(_maskz_の場合)は0クリア、そうでなければそのまま(sの値が使われる)
VEXPANDPS zmm1{k1}{z}, zmm2/m512 (V5
__m512 _mm512_mask_expand_sd(__m512 s, __mmask16 k, __m512 a)
__m512 _mm512_maskz_expand_sd(__mmask16 k, __m512 a)
__m512 _mm512_mask_expandloadu_sd(__m512 s, __mmask16 k, void* p)
__m512 _mm512_maskz_expandloadu_sd(__mmask16 k, void* p)

②の対応するビットが立っている③の要素に①の要素を下位からひとつずつ取って格納する
②の対応するビットが立っていない③の要素は、{z}指定がある場合(_maskz_の場合)は0クリア、そうでなければそのまま(sの値が使われる)
x86/x64 SIMD命令一覧表
フィードバック