AVX512対応版は→こちら
English version→x86/x64 SIMD Instruction List (SSE to AVX512)
x86/x64 SIMD命令一覧表 (SSE~AVX2)
MMXレジスタ(64ビット)の命令は割愛しました。
S1=SSE S2=SSE2 S3=SSE3 SS3=SSSE3 S4.1=SSE4.1 S4.2=SSE4.2 V1=AVX
V2=AVX2 #=64ビットモード専用
*はPS/PD/DQ を SS/SD/SI に変えるとスカラー命令(最下位のひとつのデータだけ計算)になります。
各命令の下の青字はその命令に対応するC/C++ intrinsicsの名前です。
AVX/AVX2
- SSE4.2までの命令の先頭にVをつけるとAVX命令になります。
- 実数のAVX命令でスカラーでないものはYMMレジスタで256ビット演算ができます。
- 整数のAVX命令でYMMレジスタが使えるのはAVX2からです。
- instrinsicsで256ビット命令を使うには先頭の_mmを_mm256に、末尾のsi128をsi256に変えます。
- YMMレジスタの使用には対応OSが必要です(Windowsなら7 SP1以降)。CPUIDのチェックのほかにOSのチェックが必要になります。
- YMMレジスタは基本的に上位128ビットと下位128ビットのレーンに別れて各レーンの中で動きます。横方向に動く命令(unpack, shuffle,
horizontal演算、バイトシフト、変換など)の動作は変則的になるのでマニュアルでよく確認して下さい。
うろ覚えの命令名を見つけてマニュアルを引けるようにするために作ったものです。プログラミングの際にはこの表の内容を元にせずに必ずマニュアルで確認してください。
Intelの
マニュアル→ http://www.intel.co.jp/content/www/jp/ja/processors/architectures-software-developer-manuals.html
お気づきの点がありましたらこちらのフィードバックフォーム、またはメールでページ末尾のアドレスまでご一報いただければ幸甚です。
MOVE
| |
整数 |
実数 |
YMMレーン(128bit) |
| QWORD |
DWORD |
WORD |
BYTE |
倍精度 |
単精度 |
半精度 |
XMM全体
↑↓
XMM/mem |
MOVDQA (S2
_mm_load_si128
_mm_store_si128
MOVDQU (S2
_mm_loadu_si128
_mm_storeu_si128 |
MOVAPD (S2
_mm_load_pd
_mm_loadr_pd
_mm_store_pd
_mm_storer_pd
MOVUPD (S2
_mm_loadu_pd
_mm_storeu_pd |
MOVAPS (S1
_mm_load_ps
_mm_loadr_ps
_mm_store_ps
_mm_storer_ps
MOVUPS (S1
_mm_loadu_ps
_mm_storeu_ps |
|
|
XMM上半分
↑↓
mem |
|
|
|
|
MOVHPD (S2
_mm_loadh_pd
_mm_storeh_pd |
MOVHPS (S1
_mm_loadh_pi
_mm_storeh_pi |
|
|
XMM上半分
↑↓
XMM下半分 |
|
|
|
|
|
MOVHLPS (S1
_mm_movehl_ps
MOVLHPS (S1
_mm_movelh_ps |
|
|
XMM下半分
↑↓
mem |
MOVQ (S2
_mm_loadl_epi64
_mm_storel_epi64
|
|
|
|
MOVLPD (S2
_mm_loadl_pd
_mm_storel_pd |
MOVLPS (S1
_mm_loadl_pi
_mm_storel_pi |
|
|
XMM最下位ひとつ
↑↓
r/m |
MOVQ (S2#
_mm_cvtsi64_si128
_mm_cvtsi128_si64 |
MOVD (S2
_mm_cvtsi32_si128
_mm_cvtsi128_si32 |
|
|
|
|
|
|
XMM最下位ひとつ
↑↓
XMM/mem |
MOVQ (S2
_mm_move_epi64 |
|
|
|
MOVSD (S2
_mm_load_sd
_mm_store_sd
_mm_move_sd |
MOVSS (S1
_mm_load_ss
_mm_store_ss
_mm_move_ss |
|
|
XMM全体
↑
ひとつのデータ
|
小ネタ2
_mm_set1_epi64x
VPBROADCASTQ (V2
_mm_broadcastq_epi64 |
小ネタ2
_mm_set1_epi32
VPBROADCASTD (V2
_mm_broadcastd_epi32 |
小ネタ2
_mm_set1_epi16
VPBROADCASTW (V2
_mm_broadcastw_epi16 |
_mm_set1_epi8
VPBROADCASTB (V2
_mm_broadcastb_epi8 |
小ネタ2
_mm_set1_pd
_mm_load1_pd
MOVDDUP (S3
_mm_movedup_pd
_mm_loaddup_pd
|
小ネタ2
_mm_set1_ps
_mm_load1_ps
VBROADCASTSS
memから (V1
XMMから(V2
_mm_broadcast_ss |
|
|
YMM全体
↑
ひとつのデータ |
VPBROADCASTQ (V2
_mm256_broadcastq_epi64 |
VPBROADCASTD (V2
_mm256_broadcastd_epi32 |
VPBROADCASTW (V2
_mm256_broadcastw_epi16 |
VPBROADCASTB (V2
_mm256_broadcastb_epi8 |
VBROADCASTSD
memから (V1
XMMから (V2
_mm256_broadcast_sd |
VBROADCASTSS
memから (V1
XMMから(V2
_mm256_broadcast_ss |
|
VBROADCASTF128 (V1
_mm256_broadcast_ps
_mm256_broadcast_pd
VBROADCASTI128 (V2
_mm256_broadcastsi128_si256 |
XMM
↑
複数個のデータ |
_mm_set_epi64x
_mm_setr_epi64x |
_mm_set_epi32
_mm_setr_epi32 |
_mm_set_epi16
_mm_setr_epi16 |
_mm_set_epi8
_mm_setr_epi8 |
_mm_set_pd
_mm_setr_pd |
_mm_set_ps
_mm_setr_ps |
|
|
XMM全体
↑
ゼロ |
小ネタ1
_mm_setzero_si128 |
小ネタ1
_mm_setzero_pd |
小ネタ1
_mm_setzero_ps |
|
|
| extract |
PEXTRQ (S4.1#
_mm_extract_epi64 |
PEXTRD (S4.1
_mm_extract_epi32 |
PEXTRW rへ (S2
PEXTRW r/mへ (S4.1
_mm_extract_epi16
|
PEXTRB (S4.1
_mm_extract_epi8 |
→MOVHPD (S2
_mm_loadh_pd
_mm_storeh_pd
→MOVLPD (S2
_mm_loadl_pd
_mm_storel_pd
|
EXTRACTPS (S4.1
_mm_extract_ps |
|
VEXTRACTF128 (V1
_mm256_extractf128_ps
_mm256_extractf128_pd
_mm256_extractf128_si256
VEXTRACTI128 (V2
_mm256_extracti128_si256 |
| insert |
PINSRQ (S4.1#
_mm_insert_epi64 |
PINSRD (S4.1
_mm_insert_epi32 |
PINSRW (S2
_mm_insert_epi16 |
PINSRB (S4.1
_mm_insert_epi8 |
→MOVHPD (S2
_mm_loadh_pd
_mm_storeh_pd
→MOVLPD (S2
_mm_loadl_pd
_mm_storel_pd
|
INSERTPS (S4.1
_mm_insert_ps |
|
VINSERTF128 (V1
_mm256_insertf128_ps
_mm256_insertf128_pd
_mm256_insertf128_si256
VINSERTI128 (V2
_mm256_inserti128_si256 |
unpack
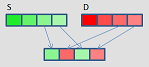 |
PUNPCKHQDQ (S2
_mm_unpackhi_epi64
PUNPCKLQDQ (S2
_mm_unpacklo_epi64 |
PUNPCKHDQ (S2
_mm_unpackhi_epi32
PUNPCKLDQ (S2
_mm_unpacklo_epi32 |
PUNPCKHWD (S2
_mm_unpackhi_epi16
PUNPCKLWD (S2
_mm_unpacklo_epi16 |
PUNPCKHBW (S2
_mm_unpackhi_epi8
PUNPCKLBW (S2
_mm_unpacklo_epi8 |
UNPCKHPD (S2
_mm_unpackhi_pd
UNPCKLPD (S2
_mm_unpacklo_pd |
UNPCKHPS (S1
_mm_unpackhi_ps
UNPCKLPS (S1
_mm_unpacklo_ps |
|
|
shuffle/permute
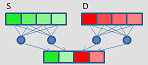 |
VPERMQ (V2
_mm256_permute4x64_epi64 |
PSHUFD (S2
_mm_shuffle_epi32
VPERMD (V2
_mm256_permutevar8x32_epi32 |
PSHUFHW (S2
_mm_shufflehi_epi16
PSHUFLW (S2
_mm_shufflelo_epi16 |
PSHUFB (SS3
_mm_shuffle_epi8 |
SHUFPD (S2
_mm_shuffle_pd
VPERMILPD (V1
_mm_permute_pd
_mm_permutevar_pd
VPERMPD (V2
_mm256_permute4x64_pd
|
SHUFPS (S1
_mm_shuffle_ps
VPERMILPS (V1
_mm_permute_ps
_mm_permutevar_ps
VPERMPS (V2
_mm256_permutevar8x32_ps |
|
VPERM2F128 (V1
_mm256_permute2f128_ps
_mm256_permute2f128_pd
_mm256_permute2f128_si256
VPERM2I128 (V2
_mm256_permute2x128_si256 |
blend
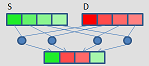 |
|
VPBLENDD (V2
_mm_blend_epi32 |
PBLENDW (S4.1
_mm_blend_epi16 |
PBLENDVB (S4.1
_mm_blendv_epi8 |
BLENDPD (S4.1
_mm_blend_pd
BLENDVPD (S4.1
_mm_blendv_pd |
BLENDPS (S4.1
_mm_blend_ps
BLENDVPS (S4.1
_mm_blendv_ps |
|
|
| move and duplicate |
|
|
|
|
MOVDDUP (S3
_mm_movedup_pd
_mm_loaddup_pd |
MOVSHDUP (S3
_mm_movehdup_ps
MOVSLDUP (S3
_mm_moveldup_ps |
|
|
| mask move |
VPMASKMOVQ (V2
_mm_maskload_epi64
_mm_maskstore_epi64 |
VPMASKMOVD (V2
_mm_maskload_epi32
_mm_maskstore_epi32 |
|
|
VMASKMOVPD (V1
_mm_maskload_pd
_mm_maskstore_pd |
VMASKMOVPS (V1
_mm_maskload_ps
_mm_maskstore_ps |
|
|
| 最上位ビット抽出 |
|
|
|
PMOVMSKB (S2
_mm_movemask_epi8 |
MOVMSKPD (S2
_mm_movemask_pd |
MOVMSKPS (S1
_mm_movemask_ps |
|
|
| gather |
VPGATHERDQ (V2
_mm_i32gather_epi64
_mm_mask_i32gather_epi64
VPGATHERQQ (V2
_mm_i64gather_epi64
_mm_mask_i64gather_epi64 |
VPGATHERDD (V2
_mm_i32gather_epi32
_mm_mask_i32gather_epi32
VPGATHERQD (V2
_mm_i64gather_epi32
_mm_mask_i64gather_epi32 |
|
|
VGATHERDPD (V2
_mm_i32gather_pd
_mm_mask_i32gather_pd
VGATHERQPD (V2
_mm_i64gather_pd
_mm_mask_i64gather_pd |
VGATHERDPS (V2
_mm_i32gather_ps
_mm_mask_i32gather_ps
VGATHERQPS (V2
_mm_i64gather_ps
_mm_mask_i64gather_ps |
|
|
変換
算術演算
比較
| |
実数 |
| 倍精度 |
単精度 |
半精度 |
スカラー比較して
結果をフラグにセット
|
COMISD (S2
_mm_comieq_sd
_mm_comilt_sd
_mm_comile_sd
_mm_comigt_sd
_mm_comige_sd
_mm_comineq_sd
UCOMISD (S2
_mm_ucomieq_sd
_mm_ucomilt_sd
_mm_ucomile_sd
_mm_ucomigt_sd
_mm_ucomige_sd
_mm_ucomineq_sd
|
COMISS (S1
_mm_comieq_ss
_mm_comilt_ss
_mm_comile_ss
_mm_comigt_ss
_mm_comige_ss
_mm_comineq_ss
UCOMISS (S1
_mm_ucomieq_ss
_mm_ucomilt_ss
_mm_ucomile_ss
_mm_ucomigt_ss
_mm_ucomige_ss
_mm_ucomineq_ss
|
|
ビット単位の論理演算
| |
整数 |
実数 |
| 倍精度 |
単精度 |
半精度 |
| and |
PAND (S2
_mm_and_si128 |
ANDPD (S2
_mm_and_pd |
ANDPS (S1
_mm_and_ps |
|
| and not |
PANDN (S2
_mm_andnot_si128 |
ANDNPD (S2
_mm_andnot_pd |
ANDNPS (S1
_mm_andnot_ps |
|
| or |
POR (S2
_mm_or_si128 |
ORPD (S2
_mm_or_pd |
ORPS (S1
_mm_or_ps |
|
| xor |
PXOR (S2
_mm_xor_si128 |
XORPD (S2
_mm_xor_pd |
XORPS (S1
_mm_xor_ps |
|
| test |
PTEST (S4.1
_mm_testz_si128
_mm_testc_si128
_mm_testnzc_si128 |
VTESTPD (V1
_mm_testz_pd
_mm_testc_pd
_mm_testnzc_pd |
VTESTPS (V1
_mm_testz_ps
_mm_testc_ps
_mm_testnzc_ps |
|
ビットシフト
| |
整数 |
| QWORD |
DWORD |
WORD |
BYTE |
| shift left logical |
PSLLQ (S2
_mm_slli_epi64
_mm_sll_epi64 |
PSLLD (S2
_mm_slli_epi32
_mm_sll_epi32 |
PSLLW (S2
_mm_slli_epi16
_mm_sll_epi16 |
|
| shift right logical |
PSRLQ (S2
_mm_srli_epi64
_mm_srl_epi64 |
PSRLD (S2
_mm_srli_epi32
_mm_srl_epi32 |
PSRLW (S2
_mm_srli_epi16
_mm_srl_epi16 |
|
| shift right arithmetic |
|
PSRAD (S2
_mm_srai_epi32
_mm_sra_epi32 |
PSRAW (S2
_mm_srai_epi16
_mm_sra_epi16 |
|
| variable shift left |
VPSLLVQ (V2
_mm_sllv_epi64 |
VPSLLVD (V2
_mm_sllv_epi32 |
|
|
| variable shift right logical |
VPSRLVQ (V2
_mm_srlv_epi64 |
VPSRLVD (V2
_mm_srlv_epi32 |
|
|
| variable shift right arithmetic |
|
VPSRAVD (V2
_mm_srav_epi32 |
|
|
バイトシフト
|
128bit |
| shift left logical |
PSLLDQ (S2
_mm_slli_si128 |
| shift right logical |
PSRLDQ (S2
_mm_srli_si128 |
| packed align right |
PALIGNR (SS3
_mm_alignr_epi8 |
文字列比較
|
explicit length |
implicit length |
| return index |
PCMPESTRI (S4.2
_mm_cmpestri
_mm_cmpestra
_mm_cmpestrc
_mm_cmpestro
_mm_cmpestrs
_mm_cmpestrz |
PCMPISTRI (S4.2
_mm_cmpistri
_mm_cmpistra
_mm_cmpistrc
_mm_cmpistro
_mm_cmpistrs
_mm_cmpistrz |
| return mask |
PCMPESTRM (S4.2
_mm_cmpestrm
_mm_cmpestra
_mm_cmpestrc
_mm_cmpestro
_mm_cmpestrs
_mm_cmpestrz |
PCMPISTRM (S4.2
_mm_cmpistrm
_mm_cmpistra
_mm_cmpistrc
_mm_cmpistro
_mm_cmpistrs
_mm_cmpistrz |
その他
LDMXCSR (S1
_mm_setcsr |
Load MXCSR register |
STMXCSR (S1
_mm_getcsr |
Save MXCSR register state |
PSADBW (S2
_mm_sad_epu8 |
Compute sum of absolute differences |
MPSADBW (S4.1
_mm_mpsadbw_epu8 |
Performs eight 4-byte wide Sum of Absolute Differences operations to produce
eight word integers. |
PMULHRSW (SS3
_mm_mulhrs_epi16 |
Packed Multiply High with Round and Scale |
PHMINPOSUW (S4.1
_mm_minpos_epu16 |
Finds the value and location of the minimum unsigned word from one of 8
horizontally packed unsigned words. The resulting value and location (offset
within the source) are packed into the low dword of the destination XMM
register. |
AESDEC (AESNI
_mm_aesdec_si128 |
Perform an AES decryption round using an 128-bit state and a round key |
AESDECLAST (AESNI
_mm_aesdeclast_si128 |
Perform the last AES decryption round using an 128-bit state and a round key |
AESENC (AESNI
_mm_aesenc_si128 |
Perform an AES encryption round using an 128-bit state and a round key |
AESENCLAST (AESNI
_mm_aesenclast_si128 |
Perform the last AES encryption round using an 128-bit state and a round key |
AESIMC (AESNI
_mm_aesimc_si128 |
Perform an inverse mix column transformation primitive |
AESKEYGENASSIST (AESNI
_mm_aeskeygenassist_si128 |
Assist the creation of round keys with a key expansion schedule |
PCLMULQDQ (PCLMULQDQ
_mm_clmulepi64_si128 |
Perform carryless multiplication of two 64-bit numbers |
VZEROALL (V1
_mm256_zeroall |
Zero all YMM registers |
VZEROUPPER (V1
_mm256_zeroupper |
Zero upper 128 bits of all YMM registers |
MOVNTPS (S1
_mm_stream_ps |
Non-temporal store of four packed single-precision floating-point values
from an XMM register into memory |
MASKMOVDQU (S2
_mm_maskmoveu_si128 |
Non-temporal store of selected bytes from an XMM register into memory |
MOVNTPD (S2
_mm_stream_pd |
Non-temporal store of two packed double-precision
floating-point values from an XMM register into memory |
MOVNTDQ (S2
_mm_stream_si128 |
Non-temporal store of double quadword from an XMM register into memory |
LDDQU (S3
_mm_lddqu_si128 |
Special 128-bit unaligned load designed to avoid cache line splits |
MOVNTDQA (S4.1
_mm_stream_load_si128 |
Provides a non-temporal hint that can cause adjacent 16-byte items within an
aligned 64-byte region (a streaming line) to be fetched and held in a small set
of temporary buffers (“streaming load buffers”). Subsequent streaming loads to
other aligned 16-byte items in the same streaming line may be supplied from the
streaming load buffer and can improve throughput. |
おまけ
小ネタ1 ゼロクリア
xor命令でできます。実数型でもできます。
例: XMM1の2個のQWORD(または4個のDWORD、8個のWORD、16個のBYTE)をすべて0にする
例: XMM1の4個のfloatに0.0fを入れる
例: XMM1の2個のdoubleに0.0を入れる
小ネタ2 ひとつの値をXMMレジスタ全体にコピーする
shuffle命令でできます。
例: XMM1の最下位32ビットに入っているfloat値をXMM1の他の3つの32bitにコピーする
例: XMM1の最下位16ビットに入っているWORD値をXMM1の他の7つの16bitにコピーする
例: XMM1の下位64ビットに入っているQWORD値をXMM1の上位64bitにコピーする
pshufd xmm1, xmm1, 44h ; 01 00 01 00 B = 44h
これはこっちのほうがいいですね。
小ネタ3 整数の符号拡張、ゼロ拡張
unpack命令でできます。
例: XMM1の8個のWORD値をDWORDにゼロ拡張してXMM1(下位4個), XMM2(上位4個)に入れる
movdqa xmm2, xmm1 ; 元データ WORD[7] [6] [5] [4] [3] [2] [1] [0]
pxor xmm3, xmm3 ; 各WORDに付加する上位16ビット=all 0
punpcklwd xmm1, xmm3 ; 下位4個分 0 [3] 0 [2] 0 [1] 0 [0]
punpckhwd xmm2, xmm3 ; 上位4個分 0 [7] 0 [6] 0 [5] 0 [4]
例: XMM1の16個のBYTE値をWORDに符号拡張してXMM1(下位8個)、XMM2(上位8個)に入れる
例(intrinsics):
__m128i 型変数words8に入っている8個のWORD値を符号拡張してdwords4lo(下位4個)、dwords4hi(上位4個)に入れる
小ネタ4 整数の絶対値
整数は2の補数なので、正または0ならば何もしない、負ならば全ビット反転後1を加える、ということをすると絶対値になります。
例: XMM1に入っている8個の符号付きWORD値の絶対値をXMM1に入れる
; 元データが正/0の場合; 元データが負の場合
pxor xmm2, xmm2
pcmpgtw xmm2, xmm1 ; xmm2←0 ; xmm2←-1
pxor xmm1, xmm2 ; 0とxor(何もしない) ; -1とxor(全ビット反転)
psubw xmm1, xmm2 ; 0を引く(何もしない) ; -1を引く(1を加える)
例(intrinsics): __m128i 型変数dwords4に入っている4個の符号付きDWORD値の絶対値をdwords4に入れる
小ネタ5 実数の絶対値
実数は補数でないので符号(最上位ビット)だけクリアすれば絶対値になります。
例: XMM1に入っている4個の単精度実数の絶対値をXMM1に入れる
; データ
align 16
signoffmask dd 4 dup (7fffffffH) ; 最上位ビットだけを落とすマスク
; コード
andps xmm1, xmmword ptr signoffmask
例(intrinsics): __m128 型変数floats4に入っている4個の単精度実数の絶対値をfloats4に入れる
const __m128 signmask = _mm_set1_ps(-0.0f); // 0x80000000
floats4 = _mm_andnot_ps(signmask, floats4);
小ネタ6 整数の乗算命令が足りない?
符号なし・符号つきで違いがあるのは上位だけです。下位は兼用できます。
符号なしWORD×WORD→上位側PMULHUW 下位側PMULLW
符号つきWORD×WORD→上位側PMULHW 下位側PMULLW
小ネタ7 MOVや論理演算で整数型と実数型があるのはなぜ?
MOV系の命令はビットパターンをそのままコピーするだけなのになぜ型ごとに別の命令があるのでしょうか?
違う動作をする? いいえ。ソフトウェア的には同じ動作です。実数としては不正かもしれない任意のビットパターンをmovapsしても大丈夫です。単精度データが入っているXMMWORDをmovdqaでXMMレジスタにロードしてそのあと単精度演算しても大丈夫です。型の違う命令でmovしてもOKなことは仕様で明確に規定されています。
違いは外からは直接見えないCPUの中の動作です。正しい型の命令を使えばCPUの中で一貫性のある動作ができるので処理が速くなる可能性があります。型がわかっている場合はその型の命令を使うのがよいでしょう。
サブルーチンの入口・出口でXMMレジスタのセーブやリストアをするときなど、どの型のデータが中に入っているか知るすべがないような場合には、型の違う命令でmovしてもちゃんと動くということです。
ビット演算命令も同じです。
小ネタ8 max・min
比較命令でマスクを得てからビット演算するとできます。
例: XMM1とXMM2に入っている各4個のDWORD値どうしを符号付き比較して小さい方をXMM1に入れる
; A=xmm1 B=xmm2 ; A>Bのとき ; A<=Bのとき
movdqa xmm0, xmm1
pcmpgtd xmm1, xmm2 ; xmm1=-1 ; xmm1=0
pand xmm2, xmm1 ; xmm2=B ; xmm2=0
pandn xmm1, xmm0 ; xmm1=0 ; xmm1=A
por xmm1, xmm2 ; xmm1=B ; xmm1=A
例(intrinsics): __m128i 型変数a, bに入っている各16個のバイト値どうしを符号付き比較して大きいほうをmaxABに入れる
小ネタ9 128ビットAVX命令とSSE命令の違いは?
多くの命令でデスティネーションにソースとは別のレジスタが使えるのでmovが要らなくなるのは自明ですがほかにも違いがあります。
一般的にAVX128ビット命令ではデスティネーションレジスタの上位にある128ビットがゼロクリアされます(例:デスティネーションにXMM0を指定するとYMM0の上位128ビットが0になります)。SSE命令では上位をいじりません。
一般的にSSE命令では16バイト境界調整が必須ですがAVX命令では16バイト境界調整しなくても実行できます(movdqA等、明示的にアラインメントを要求する命令を除く)。が性能的には調整したほうがいいでしょう。
AVX256ビット命令とAVX128ビット命令とSSE128ビット命令を混在させると著しく性能低下する場合があるようです。AVX256ビット命令とAVX128ビット命令を使う場合はSSE128ビット命令の使用を避ける(AVX128ビット命令に書き換える)のがいいかもしれません。
小ネタ10 全ビットを立てる
PCMPEQx命令でできます。
例: XMM1の2個のQWORD(または4個のDWORD、8個のWORD、16個のBYTE)をすべて-1にする
小ネタ11 整数を定数で割る
整数乗算+いくつかの命令で高速に演算できます。
例: __m128i型変数dividendsの8個の符号なしWORDを7で割って商をquotientsに格納する
// unsigned WORD integer division by constant 7 (SSE2)
// __m128i dividends 8 unsigned WORDs
__m128i t = _mm_mulhi_epu16(_mm_set1_epi16(9363), dividends);
t = _mm_add_epi16(t, _mm_srli_epi16(_mm_sub_epi16(dividends, t), 1));
__m128i quotients = _mm_srli_epi16(t, 2);
除数に応じたマジックナンバーを掛ける必要があります。このアルゴリズムの詳細とマジックナンバーの計算方法はHenry S. Warren Jr.著「Hacker's Delight」という本に詳しく書いてあります。
その本を元ネタにしてSSE/AVX intrinsicsコードジェネレーターを作りました。
ver 2023053100
ホームページ http://www.officedaytime.com/