
注意: このページはIntel SHA ExtensionsのSHA1命令の説明です。この機能に対応していないCPUでは動作しません。
SHA1は米国の政府機関が発行しているFIPS 180-4という文書がおおもとの仕様になりますのでそちらと合わせてご覧ください。
以下はFIPS 180-4の19ページに掲載されている、前処理済みの64バイト(16 DWORD)のメッセージブロックからハッシュ値を計算するアルゴリズムです。色は説明の都合上私がつけたものです。
Aの部分の処理を手助けしてくれるのがSHA1MSG1、SHA1MSG2の2つの命令です。
Bの部分の処理を手助けしてくれるのがSHA1RNDS4、SHA1NEXTEの2つの命令です。
前処理(80hをアペンドしてゼロパディングして長さを加えて64バイトの倍数長にした上で64バイトずつ区切る)の部分はSHA1命令は何もしてくれないので本稿では触れません。FIPS 180-4または他の説明をご覧ください。
Aの式は、前処理済みの64バイト(16 DWORD)のメッセージブロックの後ろにデータを追加して80 DWORDのW配列を作るための計算です。
ポイント: SHAはビッグエンディアンに基づいているため、x86/x64でSHA値を計算するには、各DWORD内のバイトオーダーを逆にする必要があります。さらに、SHA1命令を使う上では、各XMMWORD内のDWORDの順序をひっくり返す必要があります。このページでは図を見やすくするためにW配列全体をひっくり返して描いています。
Aの式では16個前、14個前、8個前、3個前のDWORDをXORしてそれを1ビット左ローテートしたものをセットしろと言っています。この方法でW16からW79まで埋めていけばいいわけです。
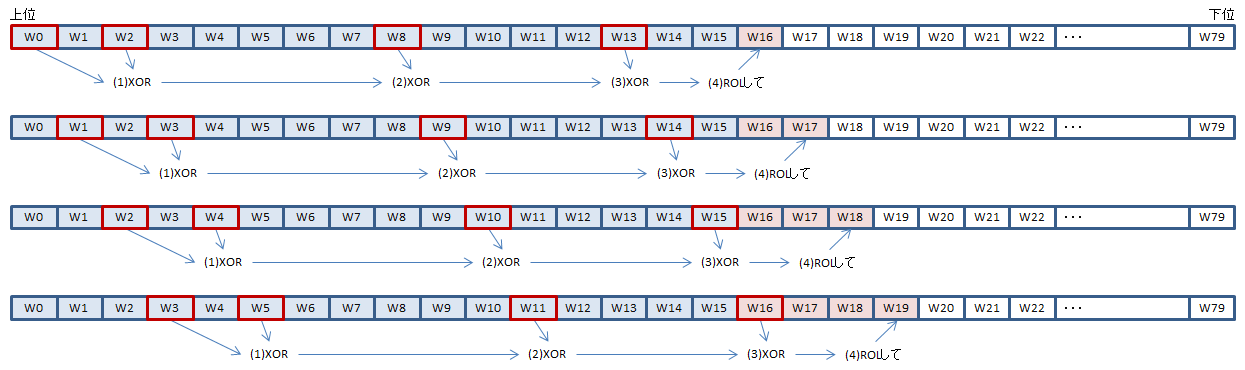
SHA1命令を使うと、これを4個ずつまとめて行うことができます。
SHA1MSG1は上図の(1)のXORを行う命令です。SHA1MSG2は上図の(3)(4)を行う命令です。(2)は普通のPXOR命令でできます。

(1)のXORを行い結果を③に返します。
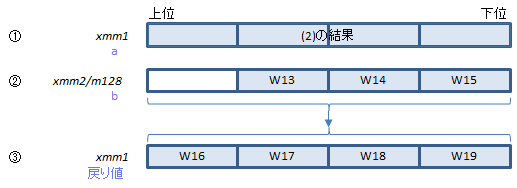
①に(2)の結果、②に3つ前からのDWORDを入れて実行すると、(3)(4)の計算を行い結果を③に返します。
Bのループではa、b、c、d、eの5個の状態変数をW配列の内容で更新していきます。
SHA1RNDS4、SHA1NEXTE命令を1回ずつ使うと、このループを4回まわる分を処理してくれます。
SHA1RNDS4命令では、状態変数を受け渡す場所が4つしかないため、a、b、c、dの4つは普通に渡しますが、eはW配列の要素に溶かし込んで(最初の要素に加算してから)渡します。
ループの最初の周回では、W0 + eを別途計算してから渡します。次回以降の周回では、SHA1NEXTE命令で、W配列の要素にeを足したデータができるのでそれを渡します。
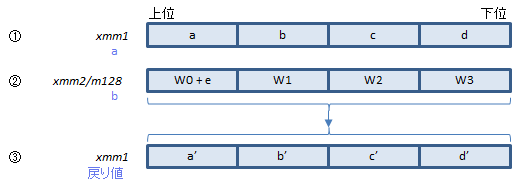
①にa~d、②にW配列の要素(ただし最初のものにはeを加える)を指定して実行すると、ループを4回まわったあとのa'~d'が得られます。
ループは合計80周まわります(SHA1RNDS4命令1回で4周分なので20回使用します)が、f()の計算方法とKの値が20周ごとに変わります。SHA1RNDS4命令では、f()とKにどれを使うかをimm8で指定します(最初の20周分(5回)はimm8=0、次の20周分(5回)はimm8=1…、最後の20周分(5回)はimm8=3)。
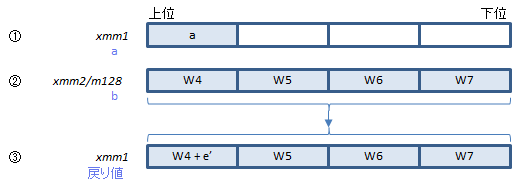
SHA1RNDS4のあとにこの命令でeを更新します。
①にa、②に次の周回で使うW配列の要素を指定して実行すると、ループを4回まわったあとのe'をW配列の最初の要素に加えたものが得られます。これを次の周回でSHA1RNDS4に渡します。
ポイントは、①に指定するのは4回まわる前のaであることです。直前のSHA1RNDS4に渡した①をコピーしておいて渡すのがよいでしょう。(Bのアルゴリズムをよく見るとわかりますが、e'の計算に必要なのは4周前のaだけなんですね。)
最後の周回ではe'単独の値が必要ですが、これは②にゼロを渡すことで得られます。あるいはH4の値を渡してそのまま足しこんでしまうという手もあるかもしれません(②の値はe'の計算には使われません。)
#pragma once
#include <intrin.h>
class SHA1H
{
protected:
// Message block
static const size_t MBYTES = 64;
unsigned char msgbuf[MBYTES];
size_t msgbuf_count; // length (in byte) of the data currently in the message block
unsigned __int64 total_count; // total length (in byte) of the message
// Intermediate hash
__m128i h0123; // h0 : h1 : h2 : h3
__m128i h4; // h4 : 0 : 0 : 0
public:
SHA1H() { Initialize(); }
~SHA1H() {}
void Update(const void* buf, size_t length);
void Final(void* digest);
protected:
void Initialize();
void ProcessMsgBlock(const unsigned char* msg);
};
#include <memory.h> #include "SHA1H.h" // Initial hash value (see FIPS 180-4 5.3.1) #define H0 0x67452301 #define H1 0xefcdab89 #define H2 0x98badcfe #define H3 0x10325476 #define H4 0xc3d2e1f0 void SHA1H::Initialize() { h0123 = _mm_set_epi32(H0, H1, H2, H3); h4 = _mm_set_epi32(H4, 0, 0, 0); msgbuf_count = 0; total_count = 0; } void SHA1H::Update(const void* buf, size_t length) { const unsigned char* p = (const unsigned char*)buf; total_count += length; // If any bytes are left in the message buffer, // fullfill the block first if (msgbuf_count) { size_t c = MBYTES - msgbuf_count; if (length < c) { memcpy(msgbuf + msgbuf_count, p, length); msgbuf_count += length; return; } else { memcpy(msgbuf + msgbuf_count, p, c); p += c; length -= c; ProcessMsgBlock(msgbuf); msgbuf_count = 0; } } // When we reach here, we have no data left in the message buffer while (length >= MBYTES) { // No need to copy into the internal message block ProcessMsgBlock(p); p += MBYTES; length -= MBYTES; } // Leave the remaining bytes in the message buffer if (length) { memcpy(msgbuf, p, length); msgbuf_count = length; } } void SHA1H::Final(void* digest) { // Add the terminating bit msgbuf[msgbuf_count++] = 0x80; // Need to set total length in the last 8-byte of the block. // If there is no room for the length, process this block first if (msgbuf_count + 8 > MBYTES) { // Fill zeros and process memset(msgbuf + msgbuf_count, 0, MBYTES - msgbuf_count); ProcessMsgBlock(msgbuf); msgbuf_count = 0; } // Fill zeros before the last 8-byte of the block memset(msgbuf + msgbuf_count, 0, MBYTES - 8 - msgbuf_count); // Set the length of the message in big-endian __m128i tmp = _mm_loadl_epi64((__m128i*)&total_count); tmp = _mm_slli_epi64(tmp, 3); // convert # of bytes to # of bits const __m128i total_count_byteswapindex = _mm_set_epi8(-1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7); tmp = _mm_shuffle_epi8(tmp, total_count_byteswapindex); // convert to big endian _mm_storel_epi64((__m128i*)(msgbuf + MBYTES - 8), tmp); // Process the last block ProcessMsgBlock(msgbuf); // Set the resulting hash value, upside down const __m128i byteswapindex = _mm_set_epi8(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15); __m128i r0123 = _mm_shuffle_epi8(h0123, byteswapindex); __m128i r4 = _mm_shuffle_epi8(h4, byteswapindex); unsigned __int32* digestdw = (unsigned __int32*)digest; _mm_storeu_si128((__m128i*)digestdw, r0123); digestdw[4] = _mm_cvtsi128_si32(r4); } void SHA1H::ProcessMsgBlock(const unsigned char* msg) { // Cyclic W array // We keep the W array content cyclically in 4 variables // Initially: // cw0 = w0 : w1 : w2 : w3 // cw1 = w4 : w5 : w6 : w7 // cw2 = w8 : w9 : w10 : w11 // cw3 = w12 : w13 : w14 : w15 const __m128i byteswapindex = _mm_set_epi8(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15); const __m128i* msgx = (const __m128i*)msg; __m128i cw0 = _mm_shuffle_epi8(_mm_loadu_si128(msgx), byteswapindex); __m128i cw1 = _mm_shuffle_epi8(_mm_loadu_si128(msgx + 1), byteswapindex); __m128i cw2 = _mm_shuffle_epi8(_mm_loadu_si128(msgx + 2), byteswapindex); __m128i cw3 = _mm_shuffle_epi8(_mm_loadu_si128(msgx + 3), byteswapindex); // Advance W array cycle // Inputs: // CW0 = w[t-16] : w[t-15] : w[t-14] : w[t-13] // CW1 = w[t-12] : w[t-11] : w[t-10] : w[t-9] // CW2 = w[t-8] : w[t-7] : w[t-6] : w[t-5] // CW3 = w[t-4] : w[t-3] : w[t-2] : w[t-1] // Outputs: // CW1 = w[t-12] : w[t-11] : w[t-10] : w[t-9] // CW2 = w[t-8] : w[t-7] : w[t-6] : w[t-5] // CW3 = w[t-4] : w[t-3] : w[t-2] : w[t-1] // CW0 = w[t] : w[t+1] : w[t+2] : w[t+3] #define CYCLE_W(CW0, CW1, CW2, CW3) \ CW0 = _mm_sha1msg1_epu32(CW0, CW1); \ CW0 = _mm_xor_si128(CW0, CW2); \ CW0 = _mm_sha1msg2_epu32(CW0, CW3); __m128i state1 = h0123; // state1 = a : b : c : d __m128i w_next = _mm_add_epi32(cw0, h4); // w_next = w0+e : w1 : w2 : w3 __m128i state2; // w0 - w3 state2 = _mm_sha1rnds4_epu32(state1, w_next, 0);// state2 = a' : b' : c' : d' w_next = _mm_sha1nexte_epu32(state1, cw1); // w_next = w4+e' : w5 : w6 : w7 // w4 - w7 state1 = _mm_sha1rnds4_epu32(state2, w_next, 0); w_next = _mm_sha1nexte_epu32(state2, cw2); // w8 - w11 state2 = _mm_sha1rnds4_epu32(state1, w_next, 0); w_next = _mm_sha1nexte_epu32(state1, cw3); // w12 - w15 CYCLE_W(cw0, cw1, cw2, cw3); // cw0 = w16 : w17 : w18 : w19 state1 = _mm_sha1rnds4_epu32(state2, w_next, 0); w_next = _mm_sha1nexte_epu32(state2, cw0); // w16 - w19 CYCLE_W(cw1, cw2, cw3, cw0); // cw1 = w20 : w21 : w22 : w23 state2 = _mm_sha1rnds4_epu32(state1, w_next, 0); w_next = _mm_sha1nexte_epu32(state1, cw1); // w20 - w23 CYCLE_W(cw2, cw3, cw0, cw1); // cw2 = w24 : w25 : w26 : w27 state1 = _mm_sha1rnds4_epu32(state2, w_next, 1); w_next = _mm_sha1nexte_epu32(state2, cw2); // w24 - w27 CYCLE_W(cw3, cw0, cw1, cw2); // cw3 = w28 : w29 : w30 : w31 state2 = _mm_sha1rnds4_epu32(state1, w_next, 1); w_next = _mm_sha1nexte_epu32(state1, cw3); // w28 - w31 CYCLE_W(cw0, cw1, cw2, cw3); // cw0 = w32 : w33 : w34 : w35 state1 = _mm_sha1rnds4_epu32(state2, w_next, 1); w_next = _mm_sha1nexte_epu32(state2, cw0); // w32 - w35 CYCLE_W(cw1, cw2, cw3, cw0); // cw1 = w36 : w37 : w38 : w39 state2 = _mm_sha1rnds4_epu32(state1, w_next, 1); w_next = _mm_sha1nexte_epu32(state1, cw1); // w36 - w39 CYCLE_W(cw2, cw3, cw0, cw1); // cw2 = w40 : w41 : w42 : w43 state1 = _mm_sha1rnds4_epu32(state2, w_next, 1); w_next = _mm_sha1nexte_epu32(state2, cw2); // w40 - w43 CYCLE_W(cw3, cw0, cw1, cw2); // cw3 = w44 : w45 : w46 : w47 state2 = _mm_sha1rnds4_epu32(state1, w_next, 2); w_next = _mm_sha1nexte_epu32(state1, cw3); // w44 - w47 CYCLE_W(cw0, cw1, cw2, cw3); // cw0 = w48 : w49 : w50 : w51 state1 = _mm_sha1rnds4_epu32(state2, w_next, 2); w_next = _mm_sha1nexte_epu32(state2, cw0); // w48 - w51 CYCLE_W(cw1, cw2, cw3, cw0); // cw1 = w52 : w53 : w54 : w55 state2 = _mm_sha1rnds4_epu32(state1, w_next, 2); w_next = _mm_sha1nexte_epu32(state1, cw1); // w52 - w55 CYCLE_W(cw2, cw3, cw0, cw1); // cw2 = w56 : w57 : w58 : w59 state1 = _mm_sha1rnds4_epu32(state2, w_next, 2); w_next = _mm_sha1nexte_epu32(state2, cw2); // w56 - w59 CYCLE_W(cw3, cw0, cw1, cw2); // cw3 = w60 : w61 : w62 : w63 state2 = _mm_sha1rnds4_epu32(state1, w_next, 2); w_next = _mm_sha1nexte_epu32(state1, cw3); // w60 - w63 CYCLE_W(cw0, cw1, cw2, cw3); // cw0 = w64 : w65 : w66 : w67 state1 = _mm_sha1rnds4_epu32(state2, w_next, 3); w_next = _mm_sha1nexte_epu32(state2, cw0); // w64 - w67 CYCLE_W(cw1, cw2, cw3, cw0); // cw1 = w68 : w69 : w70 : w71 state2 = _mm_sha1rnds4_epu32(state1, w_next, 3); w_next = _mm_sha1nexte_epu32(state1, cw1); // w68 - w71 CYCLE_W(cw2, cw3, cw0, cw1); // cw2 = w72 : w73 : w74 : w75 state1 = _mm_sha1rnds4_epu32(state2, w_next, 3); w_next = _mm_sha1nexte_epu32(state2, cw2); // w72 - w75 CYCLE_W(cw3, cw0, cw1, cw2); // cw3 = w76 : w77 : w78 : w79 state2 = _mm_sha1rnds4_epu32(state1, w_next, 3); w_next = _mm_sha1nexte_epu32(state1, cw3); // w76 - w79 state1 = _mm_sha1rnds4_epu32(state2, w_next, 3); // state1 = final a : b : c : d h4 = _mm_sha1nexte_epu32(state2, h4); // Add final e to h4 h0123 = _mm_add_epi32(state1, h0123); // Add final a:b:c:d to h0:h1:h2:h3 }