VPMOVWB - Packed MOVe Word Byte
WORD → BYTE copy lowest 8-bit.
VPMOVWB xmm1 {k1}{z}, xmm2 (V5+BW+VL
__m128i _mm_cvtepi16_epi8(__m128i a)
__m128i _mm_mask_cvtepi16_epi8(__m128i s, __mmask8 k, __m128i a)
__m128i _mm_maskz_cvtepi16_epi8(__mmask8 k, __m128i a)
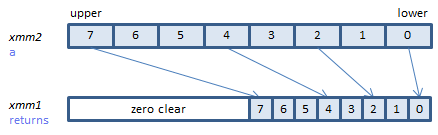
VPMOVWB m64 {k1}, xmm2 (V5+BW+VL
void _mm_mask_cvtepi16_storeu_epi8(void* d, __mmask8 k, __m128i a)
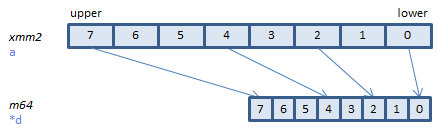
VPMOVWB xmm1 {k1}{z}, ymm2 (V5+BW+VL
__m128i _mm256_cvtepi16_epi8(__m256i a)
__m128i _mm256_mask_cvtepi16_epi8(__m128i s, __mmask16 k, __m256i a)
__m128i _mm256_maskz_cvtepi16_epi8(__mmask16 k, __m256i a)

VPMOVWB m128 {k1}, ymm2 (V5+BW+VL
void _mm256_mask_cvtepi16_storeu_epi8(void* d, __mmask16 k, __m256i a)

VPMOVWB ymm1 {k1}{z}, zmm2 (V5+BW
__m256i _mm512_cvtepi16_epi8(__m512i a)
__m256i _mm512_mask_cvtepi16_epi8(__m256i s, __mmask32 k, __m512i a)
__m256i _mm512_maskz_cvtepi16_epi8(__mmask32 k, __m512i a)

VPMOVWB m256 {k1}, zmm2 (V5+BW
void _mm512_mask_cvtepi16_storeu_epi8(void* d, __mmask32 k, __m512i a)

x86/x64 SIMD Instruction List
Feedback