
?MM/mem
_mm_load_si128
_mm_store_si128
MOVDQU (S2
_mm_loadu_si128
_mm_storeu_si128
_mm_load_pd
_mm_loadr_pd
_mm_store_pd
_mm_storer_pd
MOVUPD (S2
_mm_loadu_pd
_mm_storeu_pd
_mm_load_ps
_mm_loadr_ps
_mm_store_ps
_mm_storer_ps
MOVUPS (S1
_mm_loadu_ps
_mm_storeu_ps
_mm_mask_load_epi64
_mm_mask_store_epi64
etc
VMOVDQU64 (V5...
_mm_mask_loadu_epi64
_mm_mask_store_epi64
etc
_mm_mask_load_epi32
_mm_mask_store_epi32
etc
VMOVDQU32 (V5...
_mm_mask_loadu_epi32
_mm_mask_storeu_epi32
etc
_mm_mask_loadu_epi16
_mm_mask_storeu_epi16
etc
_mm_mask_loadu_epi8
_mm_mask_storeu_epi8
etc
mem
_mm_loadh_pd
_mm_storeh_pd
_mm_loadh_pi
_mm_storeh_pi
XMM lower half
_mm_movehl_ps
MOVLHPS (S1
_mm_movelh_ps
mem
_mm_loadl_epi64
_mm_storel_epi64
_mm_loadl_pd
_mm_storel_pd
_mm_loadl_pi
_mm_storel_pi
r/m
_mm_cvtsi64_si128
_mm_cvtsi128_si64
_mm_cvtsi32_si128
_mm_cvtsi128_si32
_mm_cvtsi16_si128
_mm_cvtsi128_si16
XMM/mem
_mm_move_epi64
_mm_load_sd
_mm_store_sd
_mm_move_sd
_mm_load_ss
_mm_store_ss
_mm_move_ss
_mm_load_sh
_mm_store_sh
_mm_move_sh

1 elem
_mm_set1_epi64x
VPBROADCASTQ (V2
_mm_broadcastq_epi64
_mm_set1_epi32
VPBROADCASTD (V2
_mm_broadcastd_epi32
_mm_set1_epi16
VPBROADCASTW (V2
_mm_broadcastw_epi16
VPBROADCASTB (V2
_mm_broadcastb_epi8
_mm_set1_pd
_mm_load1_pd
MOVDDUP (S3
_mm_movedup_pd
_mm_loaddup_pd
_mm_set1_ps
_mm_load1_ps
VBROADCASTSS
from mem (V1
from XMM (V2
_mm_broadcast_ss
1 elem
_mm256_broadcastq_epi64
_mm256_broadcastd_epi32
_mm256_broadcastw_epi16
_mm256_broadcastb_epi8
from mem (V1
from XMM (V2
_mm256_broadcast_sd
from mem (V1
from XMM (V2
_mm256_broadcast_ss
_mm256_broadcast_ps
_mm256_broadcast_pd
VBROADCASTI128 (V2
_mm256_broadcastsi128_si256
2/4/8 elems
_mm512_broadcast_i64x2
VBROADCASTI64X4 (V5
_mm512_broadcast_i64x4
_mm512_broadcast_i32x2
VBROADCASTI32X4 (V5...
_mm512_broadcast_i32x4
VBROADCASTI32X8 (V5+DQ
_mm512_broadcast_i32x8
_mm512_broadcast_f64x2
VBROADCASTF64X4 (V5
_mm512_broadcast_f64x4
_mm512_broadcast_f32x2
VBROADCASTF32X4 (V5...
_mm512_broadcast_f32x4
VBROADCASTF32X8 (V5+DQ
_mm512_broadcast_f32x8
multiple elems
_mm_setr_epi64x
_mm_setr_epi32
_mm_setr_epi16
_mm_setr_epi8
_mm_setr_pd
_mm_setr_ps
zero
_mm_setzero_si128
_mm_setzero_pd
_mm_setzero_ps
_mm_extract_epi64
_mm_extract_epi32
PEXTRW to r/m (S4.1
_mm_extract_epi16
_mm_extract_epi8
_mm_loadh_pd
_mm_storeh_pd
->MOVLPD (S2
_mm_loadl_pd
_mm_storel_pd
_mm_extract_ps
_mm256_extractf128_ps
_mm256_extractf128_pd
_mm256_extractf128_si256
VEXTRACTI128 (V2
_mm256_extracti128_si256
_mm512_extracti64x2_epi64
VEXTRACTI64X4 (V5
_mm512_extracti64x4_epi64
_mm512_extracti32x4_epi32
VEXTRACTI32X8 (V5+DQ
_mm512_extracti32x8_epi32
_mm512_extractf64x2_pd
VEXTRACTF64X4 (V5
_mm512_extractf64x4_pd
_mm512_extractf32x4_ps
VEXTRACTF32X8 (V5+DQ
_mm512_extractf32x8_ps
_mm_insert_epi64
_mm_insert_epi32
_mm_insert_epi16
_mm_insert_epi8
_mm_loadh_pd
_mm_storeh_pd
->MOVLPD (S2
_mm_loadl_pd
_mm_storel_pd
_mm_insert_ps
_mm256_insertf128_ps
_mm256_insertf128_pd
_mm256_insertf128_si256
VINSERTI128 (V2
_mm256_inserti128_si256
_mm512_inserrti64x2
VINSERTI64X4 (V5...
_mm512_inserti64x4
_mm512_inserti32x4
VINSERTI32X8 (V5+DQ
_mm512_inserti32x8
_mm512_insertf64x2
VINSERTF64X4 (V5
_mm512_insertf64x4
_mm512_insertf32x4
VINSERTF32X8 (V5+DQ
_mm512_insertf32x8
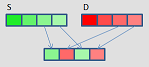
_mm_unpackhi_epi64
PUNPCKLQDQ (S2
_mm_unpacklo_epi64
_mm_unpackhi_epi32
PUNPCKLDQ (S2
_mm_unpacklo_epi32
_mm_unpackhi_epi16
PUNPCKLWD (S2
_mm_unpacklo_epi16
_mm_unpackhi_epi8
PUNPCKLBW (S2
_mm_unpacklo_epi8
_mm_unpackhi_pd
UNPCKLPD (S2
_mm_unpacklo_pd
_mm_unpackhi_ps
UNPCKLPS (S1
_mm_unpacklo_ps
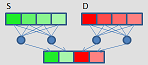
_mm256_permute4x64_epi64
VPERMI2Q (V5...
_mm_permutex2var_epi64
VPERMT2Q (V5...
_mm_permutex2var_epi64
_mm_shuffle_epi32
VPERMD (V2
_mm256_permutevar8x32_epi32
_mm256_permutexvar_epi32
VPERMI2D (V5...
_mm_permutex2var_epi32
VPERMT2D (V5...
_mm_permutex2var_epi32
_mm_shufflehi_epi16
PSHUFLW (S2
_mm_shufflelo_epi16
VPERMW (V5+BW...
_mm_permutexvar_epi16
VPERMI2W (V5+BW...
_mm_permutex2var_epi16
VPERMT2W (V5+BW...
_mm_permutex2var_epi16
_mm_shuffle_epi8
VPERMB (V5+VBMI...
_mm_permutexvar_epi8
VPERMI2B (V5+VBMI...
_mm_permutex2var_epi8
VPERMT2B (V5+VBMI...
_mm_permutex2var_epi8
_mm_shuffle_pd
VPERMILPD (V1
_mm_permute_pd
_mm_permutevar_pd
VPERMPD (V2
_mm256_permute4x64_pd
VPERMI2PD (V5...
_mm_permutex2var_pd
VPERMT2PD (V5...
_mm_permutex2var_pd
_mm_shuffle_ps
VPERMILPS (V1
_mm_permute_ps
_mm_permutevar_ps
VPERMPS (V2
_mm256_permutevar8x32_ps
VPERMI2PS (V5...
_mm_permutex2var_ps
VPERMT2PS (V5...
_mm_permutex2var_ps
_mm256_permute2f128_ps
_mm256_permute2f128_pd
_mm256_permute2f128_si256
VPERM2I128 (V2
_mm256_permute2x128_si256
_mm512_shuffle_i64x2
_mm512_shuffle_i32x4
_mm512_shuffle_f64x2
_mm512_shuffle_f32x4
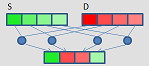
_mm_mask_blend_epi32
_mm_blend_epi32
VPBLENDMD (V5...
_mm_mask_blend_epi32
_mm_blend_epi16
VPBLENDMW (V5+BW...
_mm_mask_blend_epi16
_mm_blendv_epi8
VPBLENDMB (V5+BW...
_mm_mask_blend_epi8
_mm_blend_pd
BLENDVPD (S4.1
_mm_blendv_pd
VBLENDMPD (V5...
_mm_mask_blend_pd
_mm_blend_ps
BLENDVPS (S4.1
_mm_blendv_ps
VBLENDMPS (V5...
_mm_mask_blend_ps
_mm_movedup_pd
_mm_loaddup_pd
_mm_movehdup_ps
MOVSLDUP (S3
_mm_moveldup_ps
_mm_maskload_epi64
_mm_maskstore_epi64
_mm_maskload_epi32
_mm_maskstore_epi32
_mm_maskload_pd
_mm_maskstore_pd
_mm_maskload_ps
_mm_maskstore_ps
_mm_movemask_epi8
_mm_movemask_pd
_mm_movemask_ps
_mm_movepi64_mask
_mm_movepi32_mask
_mm_movepi16_mask
_mm_movepi8_mask
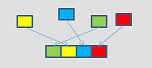
_mm_i32gather_epi64
_mm_mask_i32gather_epi64
VPGATHERQQ (V2
_mm_i64gather_epi64
_mm_mask_i64gather_epi64
_mm_i32gather_epi32
_mm_mask_i32gather_epi32
VPGATHERQD (V2
_mm_i64gather_epi32
_mm_mask_i64gather_epi32
_mm_i32gather_pd
_mm_mask_i32gather_pd
VGATHERQPD (V2
_mm_i64gather_pd
_mm_mask_i64gather_pd
_mm_i32gather_ps
_mm_mask_i32gather_ps
VGATHERQPS (V2
_mm_i64gather_ps
_mm_mask_i64gather_ps
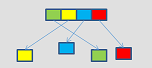
_mm_i32scatter_epi64
_mm_mask_i32scatter_epi64
VPSCATTERQQ (V5...
_mm_i64scatter_epi64
_mm_mask_i64scatter_epi64
_mm_i32scatter_epi32
_mm_mask_i32scatter_epi32
VPSCATTERQD (V5...
_mm_i64scatter_epi32
_mm_mask_i64scatter_epi32
_mm_i32scatter_pd
_mm_mask_i32scatter_pd
VSCATTERQPD (V5...
_mm_i64scatter_pd
_mm_mask_i64scatter_pd
_mm_i32scatter_ps
_mm_mask_i32scatter_ps
VSCATTERQPS (V5...
_mm_i64scatter_ps
_mm_mask_i64scatter_ps
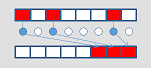
_mm_mask_compress_epi64
_mm_mask_compressstoreu_epi64
_mm_mask_compress_epi32
_mm_mask_compressstoreu_epi32
_mm_mask_compress_epi16
_mm_mask_compressstoreu_epi16
_mm_mask_compress_epi8
_mm_mask_compressstoreu_epi8
_mm_mask_compress_pd
_mm_mask_compressstoreu_pd
_mm_mask_compress_ps
_mm_mask_compressstoreu_ps
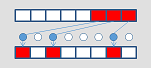
_mm_mask_expand_epi64
_mm_mask_expandloadu_epi64
_mm_mask_expand_epi32
_mm_mask_expandloadu_epi32
_mm_mask_expand_epi16
_mm_mask_expandloadu_epi16
_mm_mask_expand_epi8
_mm_mask_expandloadu_epi8
_mm_mask_expand_pd
_mm_mask_expandloadu_pd
_mm_mask_expand_ps
_mm_mask_expandloadu_ps
_mm_alignr_epi64
_mm_alignr_epi32
_mm_alignr_epi8
_mm_movm_epi64
_mm_movm_epi32
_mm_movm_epi16
_mm_movm_epi8